前言
本文主要内容
本文是面向 Python 初学者的 Scrapy 爬虫框架入门指南,旨在通过分步实战教学,帮助读者快速掌握 Scrapy 的核心使用流程。内容涵盖虚拟环境部署、框架的安装教程、创建实例项目、蜘蛛编写及数据抓取全流程,介绍如何从爬虫的响应正文提取数据,学会使用 CSS 选择器、正则表达式和 XPath 表达式,同时以 JSON Lines 格式导出到文件,最后自动化翻页获取更多的信息。本文不追求全面覆盖,聚焦基础操作,适合零基础读者快速入门网络爬虫开发。
虽然这不是一篇全面的使用教程或文档,但这是一篇用心去整理的对初学者友好的民间爬虫框架快速入门教程,尽管本文翻译整理自官方文档的初学者教程。
本文教会你以下的内容:
- 如何在 VirtualEnv 虚拟环境中安装 Scrapy;
-
创建你的第一个项目;
-
创建、编写和运行你的第一个蜘蛛;
-
进入和使用交互式控制台;
-
利用
response.css()或者response.xpath()方法来提取网页上的元素及内容; -
如何应用正则表达式来提取你想要的内容。
-
介绍什么是
Request(请求对象) 和Response(响应对象); -
区分
JSON与JSON Lines格式; -
介绍
JSON Lines的优势; -
如何跟踪链接并且解析网页代码。
基本概念简介
Scrapy 是一款基于 Python 语言的网络爬虫工具,广泛用于网页数据爬取、API 数据获取、以及进阶应用于数据挖掘、监测和自动化测试。不愧是使用广泛、易于使用、文档齐全且功能丰富强大的爬虫系统。
它提供两种爬虫机制:Spider 和 CrawlSpider,两种机制稍有区分,略有不同。
然而,想要创建一个功能全面的蜘蛛,都离不开中间件、管道和 Items。
该框架易学习、易使用,官方资料详实。虽然它用户可能是新手,但使用它抓取到想要的数据,感受到它的便利,由此不得不说,它是抓取结构化数据的必备良品。
最新版本官方手册
本文使用的 Scrapy 版本是2.13(截止到 2025-12,为最新版本),至于各种平台和各种方式怎样安装 ,请参阅《官方用户手册》:https://docs.scrapy.org/en/2.13/intro/install.html 。

系统环境和前提条件
系统环境
笔者用的机器是 Ubuntu 24.04 64位操作系统,其实只要合符于下文《前提条件》中 Python 版本的最低要求的 Linux 操作系统都可以,至于 Windows,由于篇幅原因,就不赘述,请不懂者自行百度。
前提条件
- 首先,你要会基本的 Python3 语法,特别是变量、列表和类的使用;
-
其次,你要会点 HTML 相关的知识;
-
再就是会操作 Linux 操作系统;
-
想要安装 Scrapy 当前最新版本 2.13,要求 3.9+ 的 Python 版本,这是官方手册要求的;
检查当前操作系统的 Python3 版本:
python3 --version - Ubuntu 24.04 的最新系统默认软件库中,Python 版本为 v3.12.3,满足以上的条件要求。
Ubuntu 22.04 LTS 最新的 Python 版本 3.10.12 也是合符要求的。
理论上所有 Linux 发行版,甚至 Windows 也可以安装和使用 Scrapy。
Scrapy 虚拟环境搭建教程
什么是虚拟环境,以及其特点
“虚拟环境”是一种与操作系统上 Python 周边环境相隔离的 Python 使用方式,比如:进入“虚拟环境”后,通过 pip 命令安装的包也仅仅在当前环境中生效,而是不会影响到系统上的整体环境,也不会改变除“虚拟环境”外的任何文件和目录。
虚拟环境是 Scrapy 官方手册中建议的最佳安装方式。
Ubuntu 安装 VirtualEnv
sudo apt update
sudo apt install -y python3-virtualenv
创建
cd /path/to/scrapy-project-dir
# 本文是 /codes/code/python/scrapy
mkdir /codes/code/python/scrapy
cd /codes/code/python/scrapy
virtualenv pyenv
这里创建一个虚拟环境叫“pyenv”,随着虚拟环境的建立,当前目录下同时会有个名称为“pyenv”的目录被创建。
进入
这里说的“进入”不是进入上述的“虚拟环境目录”,而是通过一行命令进入与系统的 Python 生态环境完全相隔离的“虚拟环境”,(当前还在上述“scrapy”目录中)执行:
source pyenv/bin/activate
执行以上命令后,终端中的命令行提示符会出现类似于下图的状态:

首次进入“虚拟环境”,要做的第一件事是升级 PyPI 的版本,也就是 pip 命令:
pip install -U pip
这表示当前已经进入上图中红色方框框中显示的以此命名的“虚拟环境”,这里是“pyenv”。
退出
执行以下的命令即可退出 VirtualEnv 虚拟环境:
deactivate
成功执行上述命令后,看终端命令行提示符已经恢复原样。
安装 Scrapy
进入“虚拟环境”之后,执行以下命令安装命令行工具:
pip install -U scrapy
创建爬虫项目以及运行蜘蛛
本文的用例
本文会引导你如何抓取网页数据并保存数据到本地文件中。
本文的用例来自官方手册 https://docs.scrapy.org/en/latest/intro/tutorial.html 。
用例和代码是官方手册复制过来的,本文仅仅做的是翻译成中文,并且产生一些作者的解释,仅此而已。
若有侵权请及时联系站长进行处理:admin@icxzl.com 。
创建项目
要抓取数据,首先要创建一个 Scrapy 项目。
本文的前面已经说明,要在“虚拟环境”中安装和使用 Scrapy,所以首先进入“虚拟环境”。
然后是在当前目录下创建一个项目:
scrapy startproject tutorial
成功执行以上命令后,将在本目录中创建一个名为 tutorial 的目录,这是项目的根目录。
项目目录的初始结构组成
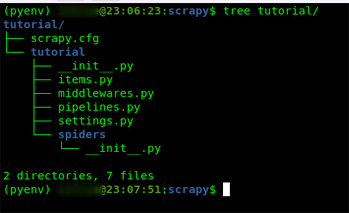
项目根目录下有一个部署爬虫的配置文件 scrapy.cfg 以及与项目同名的 Python 模块目录(其实就是编写爬虫代码所在的目录),于是默认的项目目录结构如下:
tutorial/
scrapy.cfg # 部署配置文件。对整个 Scrapy 项目的部署
tutorial/ # 项目的 Python 模块,所有该项目的代码将在这个目录下生成和编写。
__init__.py
items.py # 项目条目定义文件。该文件定义要抓取的信息条目
middlewares.py # 项目中间件文件。定义 HTTP 请求的发出和收到响应过程中的处理操作
pipelines.py # 项目管道文件。管道文件处理条目(Items),它定义如何保存和处理条目
settings.py # 项目设置文件。负责定义基本信息、并发请求数目、注册中间件和管道等等任务
spiders/ # 稍后你将放置蜘蛛的目录。爬虫抓取的程序逻辑代码文件所在目录。
__init__.py
实际上如下图:
创建蜘蛛(Spider)
爬虫框架中干活的是蜘蛛,所以必需创建蜘蛛代码文件,也就是在 tutorial/spiders 目录中创建一个能够抓取网上信息的代码文件。
通过命令行工具创建
通过命令行工具自动地创建你想要的蜘蛛:
scrapy genspider [options] <name> <domain>
- 其中
name是爬虫项目中唯一识别名称,也就是说,项目中只能有一个这样的名称,同一项目中,别的蜘蛛是不能再起个这样的名称的。 -
domain为要抓取数据的网站或 API 的域名,可以是一个 HTTP URL。 -
options是可选的,可以过scrapy genspider --help查看所有支持的参数选项。
执行以下命令创建一个名为 quotes 的蜘蛛:
# 当前所有目录为: /codes/code/python/scrapy
# 进入上述目录的 tutorial 目录,这是项目的根目录,
# 以后如果没有特别的要求,默认执行 scrapy 命令的目录是此目录
cd tutorial/
# 蜘蛛目录在于当前目录的 tutorial/Spider 子目录
scrapy genspider "quotes" "https://quotes.toscrape.com/page/1/"
代码创建完成
于是,一个文件名为 quotes.py 的 Python 文件在 tutorial/Spider 目录被 scrapy genspider 命令创建了,该文件内容默认为:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/page/1/"]
def parse(self, response):
pass
文档中的示例代码
在官方文档中,需要以下的代码:
from pathlib import Path
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
"https://quotes.toscrape.com/page/1/",
"https://quotes.toscrape.com/page/2/",
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f"quotes-{page}.html"
Path(filename).write_bytes(response.body)
self.log(f"Saved file {filename}")
其中:
name:项目中的唯一识别名称;start_requests():爬虫开始的目标网址,数据的抓取从这些网址开始。该方法必须返回一个可迭代的值。该可迭代的值可以返回一个包含若干 HTTP 请求列表或者生成器;parse():该方法用来解析 HTTP 响应,以及发起新的请求(如果需要的话);很多时候用来处理获取的数据,并且与Items(更多资料:https://docs.scrapy.org/en/latest/topics/items.html) 相关联。这是个默认的方法,当 Request 对象没有指定回调方法时就采用该方法。
该方法的
response参数包含爬虫的 HTTP 响应返回的相关数据,比如响应体,其中包含网页的 HTML 代码或者 API 数据。又或者是响应状态代码,如200、404等。
把上述代码复制粘贴到 tutorial/spiders/quotes.py 文件中。
更简洁的代码,做同样的事情
上文提到, parse() 方法是 scrapy.Request 对象构造方法的默认回调方法。
然而,可以使用以下的代码做上文的代码相同的事情:
from pathlib import Path
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/page/1/",
"https://quotes.toscrape.com/page/2/",
]
def parse(self, response):
page = response.url.split("/")[-2]
filename = f"quotes-{page}.html"
Path(filename).write_bytes(response.body)
运行蜘蛛
在项目根目录(/codes/code/python/scrapy/tutorial/)运行爬虫。
运行命令格式如下:
scrapy crawl [options] <spider>
其中:
options:表示运行爬虫时的一些可选项,比如设置 Items 的保存输出文件等。具体的所有可选项通过命令
scrapy crawl --help查看。-
spider:表示本文前面所定义的name,也就是项目中唯一的名称。
在项目根目录中执行以下命令来运行爬虫 quotes:
scrapy crawl quotes
爬虫成功运行的话,会输出类似于下图的情况:
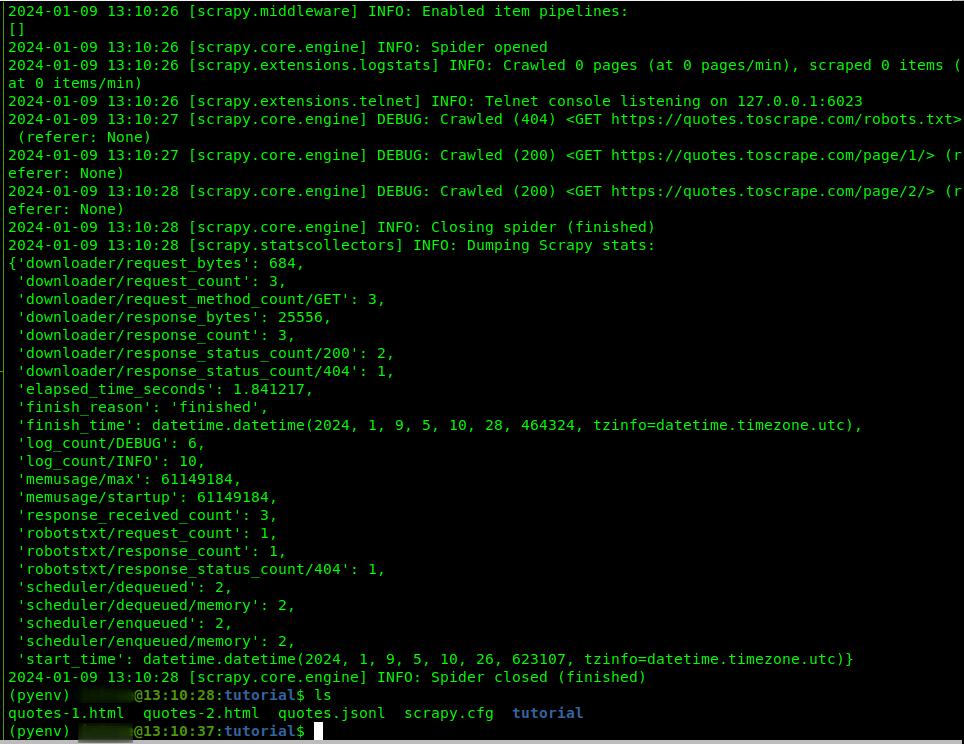
执行爬虫运行命令后,项目根目录会生成两个 .html 文件。依照代码可以看出,这两个文件正好是 start_requests() 方法中的变量 urls 定义的两个 URL 的 HTTP 响应内容,文件装着的是 HTML 代码。
2. 蜘蛛的基本运行逻辑
从 start() 方法(通过 scrapy.Request 对象)发出 HTTP 请求,到通过 scrapy.Response 对象实例来接收响应,再调用 parse() 方法来处理响应内容。
响应正文往往是结构化数据,如果响应体的内容是 HTML 代码,可根据需求利用蜘蛛类的 parse() 方法的参数同时也是对象 scrapy.Response 的实例 response 变量的元素选择器来提取信息。
总结起来就是,Scrapy的工作流程遵循经典的请求-响应模式:
- 通过
scrapy.Request发起HTTP请求 - 接收
scrapy.Response响应对象 - 在
parse()方法中处理响应
关于
scrapy.Request跟scrapy.Response两个对象的更多解释,可参考文档:https://docs.scrapy.net.cn/en/latest/topics/request-response.html
3. 交互式调试:Scrapy Shell 的入门与进阶
官方文档建议在Scrapy Shell 环境下学习如果提取数据,并且是最佳学习途径。
更多资料,请移步:https://docs.scrapy.net.cn/en/latest/topics/shell.html 。
如何解析结构化数据:https://docs.scrapy.net.cn/en/latest/intro/tutorial.html#extracting-data 。
基本概念
Scrapy Shell 是用于抓取给定的 URL 或文件中结构化数据的交互式控制台,用于快速测试数据提取规则。
在控制台下可以尝试诸多的 Scrapy API 快捷方式和各种对象的操作和行为来测试从而掌握这些能够在蜘蛛中用的方法和对象。
官方文档建议在 Scrapy shell(下称“交互式控制台”) 环境下学习数据提取方法,并且是最佳学习途径。
response 变量是何物
Scrapy 官方文档的教程(Tutorial)中,将介绍使用对象实例 response 提取 HTML 文本中的结构化数据。这里的 response 变量与蜘蛛代码中的 parse() 方法的同名参数变量是同一个变量,或者说都是 scrapy.Response 这个对象的实例。也就是说它们拥有的类属性和类方法是一致的。
文档中,介绍了如何使用 response 变量获取 HTML 文档中的结构化数据。
交互式控制台的用法
一、创建一个 Shell 会话
用法如下:
scrapy shell [url|file]
url指的是远程文档的网址;file指的是电脑本地的文件的全路径。
也就是说,既可从远程文档中获取结构化数据,也可从本地的特定文件的内容中获取数据。
更多的选项请参阅 HELP 文档: scrapy shell --help。
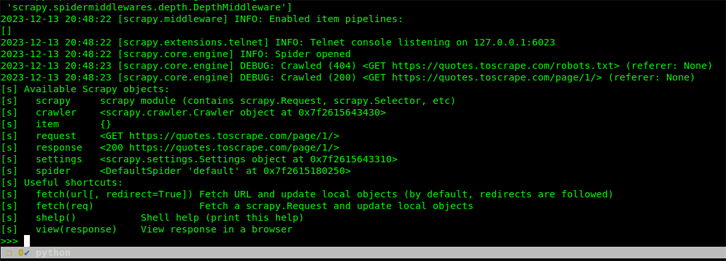
官方文档的教程中,以远程 URL https://quotes.toscrape.com/page/1/ 为例,进入交互式控制台:
scrapy shell "https://quotes.toscrape.com/page/1/"
执行上面命令将会出现类似下图的界面:
二、基本使用
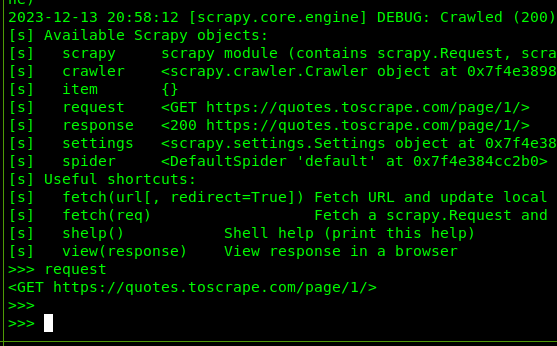
进入控制台即可使用之,可在 >>> 提示符后面输入想要运行的对象、属性、函数和方法等 Scrapy API。
比如:
执行 request 能够获取当前基本请求信息:
执行 response 能够获取 HTTP 响应的基本信息:
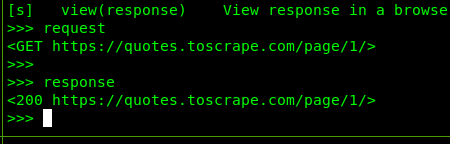
执行 response.status 获取当前响应的状态码,如 200、404 等:
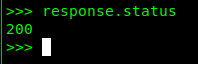
200 表示当前 HTTP 请求并接收响应成功,而 response.body 则打印出响应体的文本。
response.attributes 和 request.attributes 可分别获取所有它们拥有的类属性:

Request 和 Response 对象的更多资料,请移步:https://docs.scrapy.org/en/latest/topics/request-response.html 。
三、退出当前会话
执行 quit() 函数即可退出控制台。
Scrapy 数据提取核心技术:CSS 与 XPath 选择器
Scrapy 数据提取工作原理其实不难理解,就是按用户的需求应用爬虫内置的 API 或者 Python 正则表达式把一项项数据解析出来。
比如:获取 HTML 文档中的某项内容,可以使用 Scrapy 提供的 CSS 或 XPath 选择器,两者都是爬虫系统内置的 API,也可以使用正则表达式,来获取想要的内容。
甚至可以用外部的库来解析内容,比如 BeautifulSoup。
本章节覆盖 CSS 选择器使用技巧,XPath 表达式应用案例,以及 Scrapy Shell 数据提取的调试方法详解。
什么是 CSS 和 XPath
系统对 Scrapy 数据提取内置着两套方案,一是 CSS 选择器,另一个是 XPath 表达式,它们都是 Response 对象的方法,同时也是 scrapy.Selector 对象的方法。
接下来的文章内容开始大篇幅讲解如何使用上述的两套方案:
比如:
response.xpath(query):它是TextResponse.selector.xpath(query)的快捷方式,利用 XPath 表达式来选择元素;-
response.css(query):它是TextResponse.selector.css(query)的快捷方式。
它们都有各自的语法,并且才能方便地提取到结构化数据。
query 指查询的语句,语句要符合两者分别的语法。
其中 response.css() 的提取语法类似于著名且广泛使用的 JavaScript 类库 jQuery 的选择器语法。
具体的详细介绍可参考: https://www.w3.org/TR/selectors/ 。
以及官方文档: https://docs.scrapy.org/en/latest/topics/selectors.html 。
这里不多说,就举几个应用的例子。
使用 CSS 选择器提取数据
获取网页的标题选择器对象
在 HTML 元素中,有个 title 元素,它里面装的是网页的标题,也正是当前要获取的内容所在元素。
这里在控制台环境下,要获取网页 https://quotes.toscrape.com/page/1/ 的页面标题:
response.css("title")
上面的代码将获取的是关于 HTML title 元素类似于列表的选择器对象(SelectorList),想要提取出元素的内容,需要执行以下的代码:
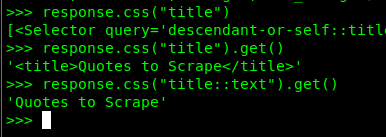
获取单个元素
response.css("title::text").get()
::text表示 HTML 元素的内容(不包括 HTML 标签自身),如果就这样执行,也是会获取到一个选择器对象;-
.get()则表示获取元素字符串内容,返回值不是个 Python 对象。此方法仅仅获取一次内容,想要获取多个文本内容组成的列表,则需要使用
.getall()。
上面的代码执行结果:
获取所有匹配元素
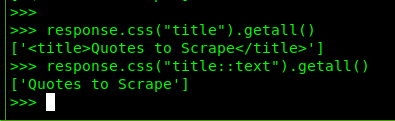
当然,正常情况下,一个 HTML 文档中仅有一个 title 元素,本章节就举个例子,把它当作有很多。
使用 .getall() 方法,若是只有一个 HTML 的元素,那么将仅仅获取该元素的内容,并且执行结果也不是个字符串,而是由一个字符串组成的列表。
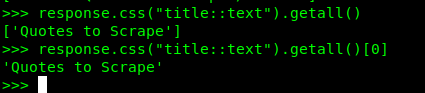
response.css("title::text").getall()
执行结果以下图:
此时要获取内容,需要在上面代码的后面加上列表的索引,因为是第一个,所以索引是 0:
response.css("title::text").getall()[0]
执行结果:
应用正则表达式来获取内容
获取 HTML 元素内容时,除了使用 get() 和 getall() 方法,还可以用更加灵活的正则表达式来提取想要的内容字符串。
response.css() 方法返回的是一个类列表的选择器列表对象,此对象有个方法 re(regex) 能用正则表达式来获取匹配的内容。
re() 方法采用的是 Python 标准的正则表达式,有兴趣了解更多可访问: https://docs.python.org/zh-cn/3/library/re.html 。
从上文可知,当前网页中的标题内容为:
Quotes to Scrape
- 从元素内容中获取字符个数为 6 的单词:
response.css("title::text").re(r"\w{6}")执行结果:
['Quotes', 'Scrape'] - 获取标题内容前后两个单词,即不要 “to” 以及其前后的空格:
response.css("title::text").re(r"(\w+) to (\w+)")执行结果:
['Quotes', 'Scrape'] - 获取标题的全部内容:
response.css("title::text").re(r".+")执行结果:
['Quotes to Scrape']
由上述的执行结果可以得出结论:re() 方法得到一个由匹配字串组成的列表,是 Python 的普通列表,可用下标索引来访问里面的字串。
XPath 提取数据
据文档描述:XPath 表达式非常强大,它是 Scrapy 的基础选择器,就连本文前面但要的 CSS 选择器也是基于它。事实上,CSS 选择器在底层被转换为 XPath。
XPath 能选择的范围远不是 CSS 选择器能比的,它还可以通过测试是否包含一段字符串而选择其所在的元素,使用方式: response.xpath("//element[contains(选择器,'包含的文本字符串')]");比如,可以选择元素内容包含“下一页”的锚链接,此时要用 response.xpath("//a[contains(.//text(),'Next')]") 来选择,若是匹配,则返回的是包含该锚链接的选择器对象列表,而这个锚链接全貌可能是 <a href="https://domain.com/page/2">下一页</a>。
- 用
.xpath(query)选择title元素:response.xpath("//title")执行结果:

-
用
.xpath(query)得到title元素的内容:response.path("//title/text()").get()执行结果:
-
使用 XPath 选择“下一页”的锚链接:
response.xpath("//a[contains(.//text(),'Next')]")执行结果:
-
使用 XPath 获取“下一页”的锚链接中的 URL:
response.xpath("//a[contains(.//text(),'Next')]/@href").get()执行结果:




更多关于 XPath 的资料请参阅 W3C 的标准:XML Path Language (XPath) 3.1 。
在浏览器中打开当前获取的网页
上文的对于用 response.css() 用法的演示都是使用 HTML 标题元素,然而,网页上通常只有一个 title 元素。
而爬虫要抓取的数据有时是复杂的,至少比取得标题要复杂得多,可能一个查询规则会返回多个元素或/和内容,这时就要深入地研究网页的构成。
一般情况下,可以用浏览器通过网址访问该远程网页,然后查看网页源代码,再从源代码找到想要的元素和内容,最后才用 .css() 来选择全需求的内容。
如果读者不想访问远程的网址,可以在 Scrapy shell 通过执行 view(response) 在浏览器打开当前的网页,这访问的是本地的副本,不是远程的。
浏览器显示的网页:
当然,网页上的 CSS/JS 等资源还是要从远程获取的,但是这无关紧要,要的仅是网页的代码。
在 Scrapy Shell 中调试提取数据的方法
现在你已经了解了一些有关选择和提取的知识,接下来完成通过编写蜘蛛的代码从网页中提取名言和作者字符串。
在网站 https://quotes.toscrape.com/ 的 HTML 源代码中,包含名言和作者的 HTML 元素结构如下所示:
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text"
>“The world as we have created it is a process of our thinking. It
cannot be changed without changing our thinking.”</span
>
<span
>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta
class="keywords"
itemprop="keywords"
content="change,deep-thoughts,thinking,world"
/>
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
网页上有多个像这样的结构,所以只要匹配,会一次获取多个不同的名言和作者。
启动交互控制台测试一下提取数据的规则
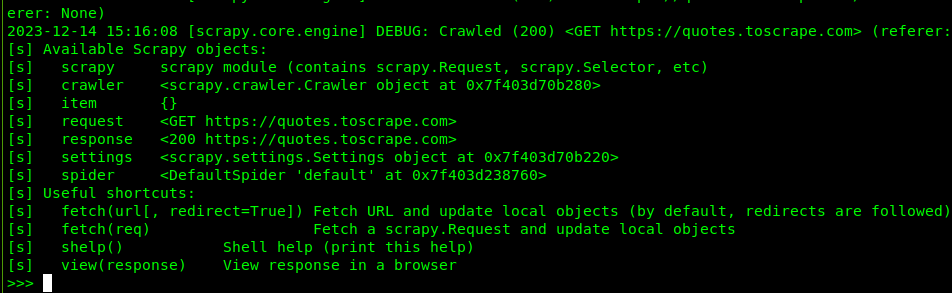
进入 Shell:scrapy shell 'https://quotes.toscrape.com'。
刚进入的界面如下图所示:
一、从 HTML 结构中获取多个不同元素及其元素值
我们要从网页的 HTML 代码中提取出名言、作者和标签,其中,从分析 HTML 代码可知,单个独立的 div class="quote" 中有一项名言、一项作者以及若干项标签。而一个页面中有若干个 div class="quote"。
- 获取
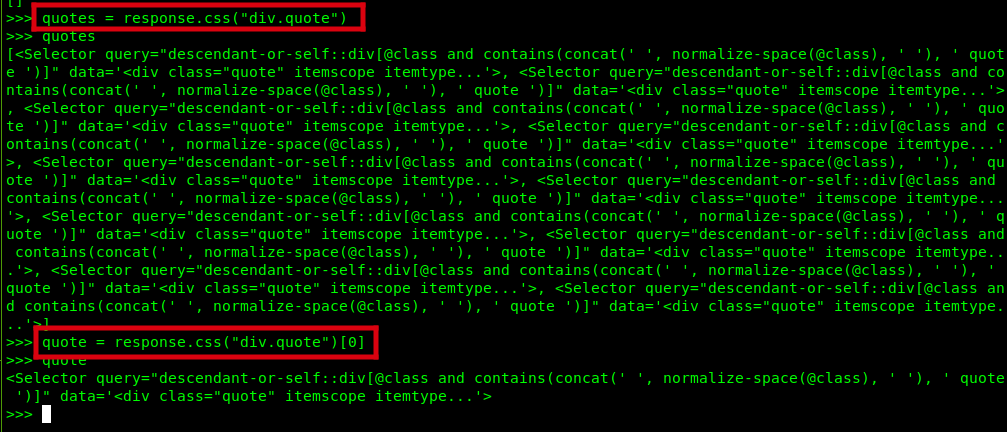
div.quote,并把选择器列表赋值给变量,以备以后使用:# 获取所有的名言 HTML 结构 quotes = response.css("div.quote") # 获取第一个名言 HTML 结构 quote = response.css("div.quote")[0] quotes quote执行结果:
-
获取“名言”:“名言”所在的结构是
div.quote > span.text,因此:quote.css("span.text::text").get()执行结果:
-
获取“作者”:“作者”所在的结构是
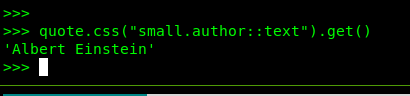
div.quote > span > small.author:quote.css("small.author::text").get()执行结果:
-
获取“标签”:“标签”所在结果是
div.quote > div.tags > a.tag:quote.css("div.tags>a.tag::text").getall()执行结果:


二、迭代所有的“名言”元素
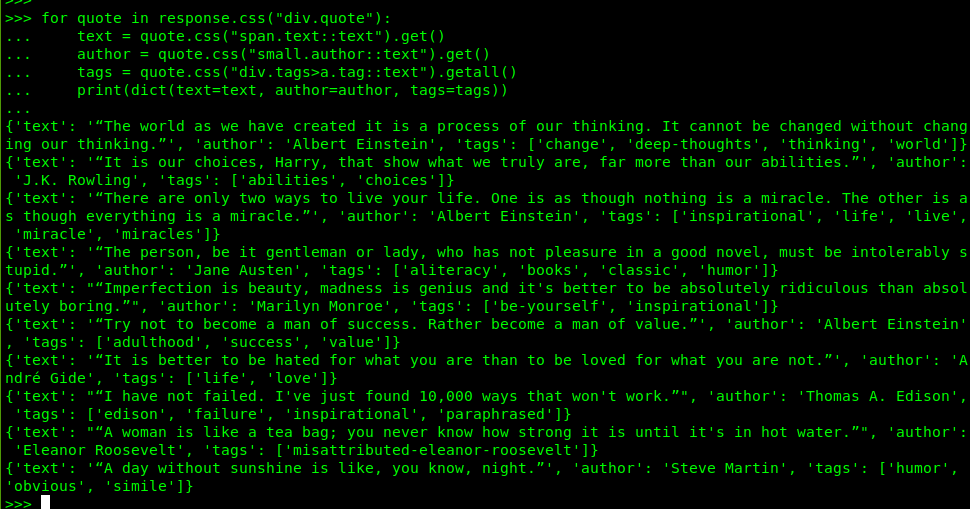
for quote in response.css("div.quote"):
text = quote.css("span.text::text").get()
author = quote.css("small.author::text").get()
tags = quote.css("div.tags>a.tag::text").getall()
print(dict(text=text, author=author, tags=tags))
执行结果:
Scrapy 数据提取实战案例
本文的前面部分介绍了如何在下载的网页提取数据,这一部分将说明如何在蜘蛛代码中应用上述的提取数据的技能。
通常蜘蛛会爬取很多的网页,每个网页又提取很多数据项。这种情况下需要用到 yield 关键词,它会将每次迭代提取的数据项打印在终端上,或者输送到数据库或文件中。
现在你已经了解了一些有关选择和提取的知识,接下来完成通过编写蜘蛛的代码从网页中提取数据。
最简单的 Scrapy 爬虫实例
将原有的文件清空,然后复制粘贴以下的代码到文件中(这里是 tutorial/spiders/quotes.py):
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/page/1/",
"https://quotes.toscrape.com/page/2/",
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}
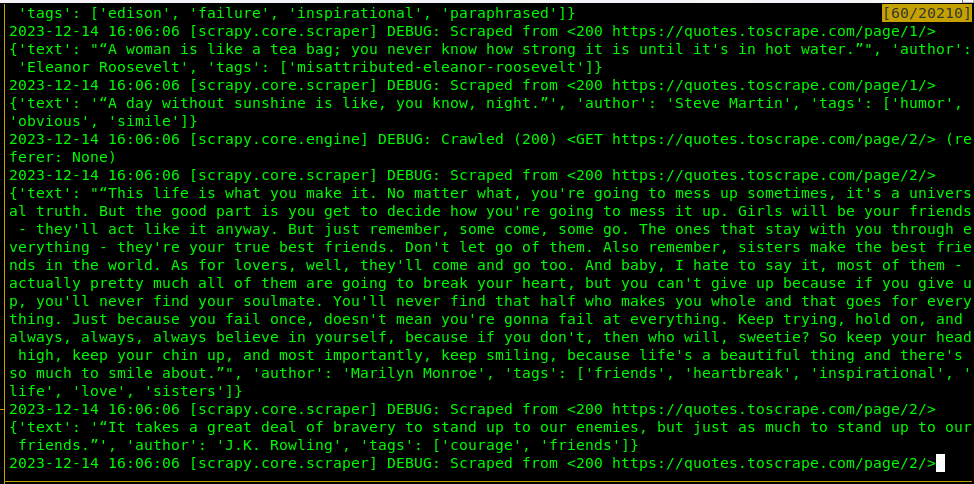
运行
scrapy crawl quotes
执行的部分结果:
停止运行
按下键盘上的 Ctrl + D 组合键即可,按一次不停止,就按多次。
这是个简单的爬虫案例,实际应用中,蜘蛛可以编写得很复杂。
那么,Scrapy 爬虫爬取的数据怎样处理储存呢?一般有两种方式,一是写入文本文件,二是存入数据库。
由于数据库要额外学习,在本教程的宗旨是快速入门,因此,容易写入和读取的文本文件成为本文使用的数据存放方式。
接下来介绍两种常见的文本数据文件格式:JSON Lines 和 JSON。
数据存储格式
最简单的提取数据的储存方式是用文件,一般序列化的数据使用 .json 和 .jsonl 两种数据导出方式的文件类型。
Scrapy 官方文档建议采用
JSONL文件格式保存提取的数据。
JSON Lines 文件格式
JSON 行(JSON Lines)文本格式,也称为换行分隔的 JSON。JSON 行是一种存储结构化数据的方便格式,能够一次处理一条记录,每行是单独的一条数据,这与 JSON 格式明显不同。它适用于 unix 风格的文本处理工具和 Shell 管道。这是一种很好的日志文件格式。它还是在协作进程之间传递消息的灵活格式。
JSON Lines 文件内容的格式如下:
{"text": "“I like nonsense, it wakes up the brain cells. Fantasy is a necessary ingredient in living.”", "author": "Dr. Seuss", "tags": ["fantasy"]}
{"text": "“I may not have gone where I intended to go, but I think I have ended up where I needed to be.”", "author": "Douglas Adams", "tags": ["life", "navigation"]}
{"text": "“The opposite of love is not hate, it's indifference. The opposite of art is not ugliness, it's indifference. The opposite of faith is not heresy, it's indifference. And the opposite of life is not death, it's indifference.”", "author": "Elie Wiesel", "tags": ["activism", "apathy", "hate", "indifference", "inspirational", "love", "opposite", "philosophy"]}
...
JSON Lines有以下的特点:
- 使用 UTF-8 编码;
-
每行都是一个合法的 JSON 值(JSON 序列化的值,只是不包含方括号);
-
行分隔符是’\n’,但是 ‘\r\n’ 也会被接受;
然而处理
JSON Lines文件的每一行时,忽略掉行分隔符,就好像没有分隔符一般,这给了用户极大的方便; -
建议约定用以
.jsonl为后缀的文件保存JSON Lines的内容。- 建议使用 gzip 或 bzip2 等流压缩器来节省空间,从而生成 .jsonl.gz 或 .jsonl.bz2 文件。
.jsonl文件的 MIME 类型可能是application/jsonl,但是它至今还没有标准化。- 文件内行的称呼问题:文本编辑器中称第一行为“行1”,而在 JSON Lines 文件中的第一个值称呼为“值1”。
JSON 文件格式
JSON 全称“JavaScript Object Notation”,是一种通用的数据保存格式,它以字典和列表的形式储存在文本文件中。
JSON 文件内容的格式大致如下:
[ {"text": "“I like nonsense, it wakes up the brain cells. Fantasy is a necessary ingredient in living.”", "author": "Dr. Seuss", "tags": ["fantasy"]},
{"text": "“I may not have gone where I intended to go, but I think I have ended up where I needed to be.”", "author": "Douglas Adams", "tags": ["life", "navigation"]},
{"text": "“The opposite of love is not hate, it's indifference. The opposite of art is not ugliness, it's indifference. The opposite of faith is not heresy, it's indifference. And the opposite of life is not death, it's indifference.”", "author": "Elie Wiesel", "tags": ["activism", "apathy", "hate", "indifference", "inspirational", "love", "opposite", "philosophy"]},
...
]
而 JSON Lines 文件内容的格式如下:
{"text": "“I like nonsense, it wakes up the brain cells. Fantasy is a necessary ingredient in living.”", "author": "Dr. Seuss", "tags": ["fantasy"]}
{"text": "“I may not have gone where I intended to go, but I think I have ended up where I needed to be.”", "author": "Douglas Adams", "tags": ["life", "navigation"]}
{"text": "“The opposite of love is not hate, it's indifference. The opposite of art is not ugliness, it's indifference. The opposite of faith is not heresy, it's indifference. And the opposite of life is not death, it's indifference.”", "author": "Elie Wiesel", "tags": ["activism", "apathy", "hate", "indifference", "inspirational", "love", "opposite", "philosophy"]}
从以上的举例可以看出, JSON 格式有明显的局限性,如果往文件添加数据,它将会再追加一个 JSON 格式的数据,就像如下:
[
{"text": "“I like nonsense, it wakes up the brain cells. Fantasy is a necessary ingredient in living.”", "author": "Dr. Seuss", "tags": ["fantasy"]},
{"text": "“I may not have gone where I intended to go, but I think I have ended up where I needed to be.”", "author": "Douglas Adams", "tags": ["life", "navigation"]},
...
][
{"text": "“Try not to become a man of success. Rather become a man of value.”", "author": "Albert Einstein", "tags": ["adulthood", "success", "value"]},
{"text": "“It is better to be hated for what you are than to be loved for what you are not.”", "author": "André Gide", "tags": ["life", "love"]},
...
]
毫不意外,这就破坏了 JSON 约定俗成的格式。
而 JSON Lines 数据的添加则更简单,并一如既往地易读取和写入,就是在原先的文件内容的末尾追加若干行。
由此可见,以行(一行为一个值)为单位的 JSON Lines 格式更适合读取和添加数据,而 JSON 格式更易序列化和反序列化。
导出爬虫提取的数据
准备将数据输出到文件,这里采用建议的 JSON Lines 格式。
需要用到 -o 选项。导出数据的命令格式为:scrapy crawl 蜘蛛名称 -o 文件名.文件格式,-o 选项表示将数据追加到文件中,不会覆盖原有的文件内容。
然而,如果用选项 -O(大写的字母 o) 会覆盖原文件。
具体的选项列表在 scrapy crawl --help。
导出爬取到的数据到文件 quotes.jsonl,并且以追加内容的方式:
scrapy crawl quotes -o quotes.jsonl
程序会自动识别导出的文件格式。
执行结果:

此章节运行一个爬虫例子,演示了 Scrapy 如何导出 JSON Lines 格式数据,倘若要保存到 JSON 文件,那么仅须将 -o quotes.jsonl 更换为 -o quotes.json,系统会自动识别。
爬虫自动跟踪链接
通过获取指向下一页的链接来抓取更多的数据就是跟踪链接,获得下一个要爬取的 URL。
利用响应对象从结构化文本获取下一页链接
根据浏览器工具的检查可知,页面 https://quotes.toscrape.com/ 的下一页链接文字“Next”所在的 HTML 结构如下所示:
<ul class="pager">
<li class="next">
<a href="/page/2/">Next <span aria-hidden="true">→</span></a>
</li>
</ul>
前文就介绍到交互式命令行,在里面可以测试提取数据的查询规则。
创建并进入会话:scrapy shell "https://quotes.toscrape.com/" 。
经过调试,就可以把这些规则和代码写入到蜘蛛代码文件中,让蜘蛛正确地爬取和处理数据。
比如,获取 Next 所在的锚链接的 href 属性,可执行以下的代码:
response.css("li.next a::attr(href)").get()
执行结果:
'/page/2/'
也可以使用 attrib 属性做与上述同样的事情:
response.css("li.next a").attrib["href"]
关于元素属性可参考:https://docs.scrapy.org/en/latest/topics/selectors.html#selecting-attributes 。
翻页跟踪实现
复制粘贴以下的代码到蜘蛛 quotes 代码文件中:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/page/1/",
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}
next_page = response.css("li.next a::attr(href)").get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
代码解释:
start_urls是一个 URL 列表,列表里面的 URL 会自动放进 Scrapy 蜘蛛请求队列中,并且会自动地下载相关的 HTML 代码,然后将响应对象的实例交给parse()方法,这是蜘蛛中默认的响应处理方法;-
yield在 Python 中表示脚本代码解释器执行到这一步才让返回它所代表的数据,其他时候时时处于待命状态,这不同于return关键词; -
response.urljoin()方法合并响应 URL 与相对 URL(这里是以 http 开头的首页 URL 与分页的相对 URL),从而组成一个绝对 URL;若下一页的链接不是个相对 URL,那么这里就不用该方法,可直接把
.get()方法提取到的 URL 作为第一个参数传递进scrapy.Request()方法中; -
yield scrapy.Request(next_page, callback=self.parse)该行代码将对每一个由下一页锚链接提取的 URL 进行爬取。
运行:
scrapy crawl quotes -o quotes.jsonl
执行上述命令将会爬取所有页面,从而提取所有页面中想要的信息。
执行结果:

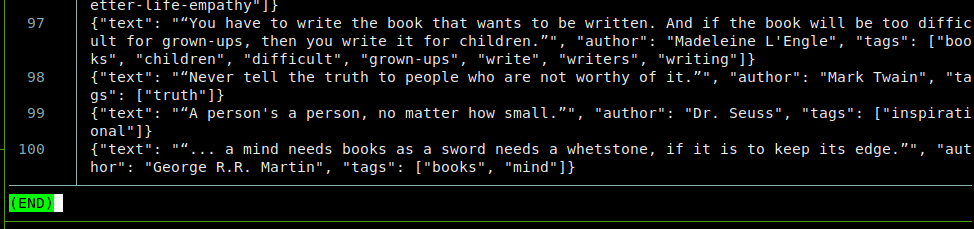
数据导出的文件名为 quotes.jsonl,它的文件内容中每一行分别为一个值,值是个序列化的字典,里面包含每次提取的数据,然后一行行地写入文件。
quotes.jsonl 文件头:
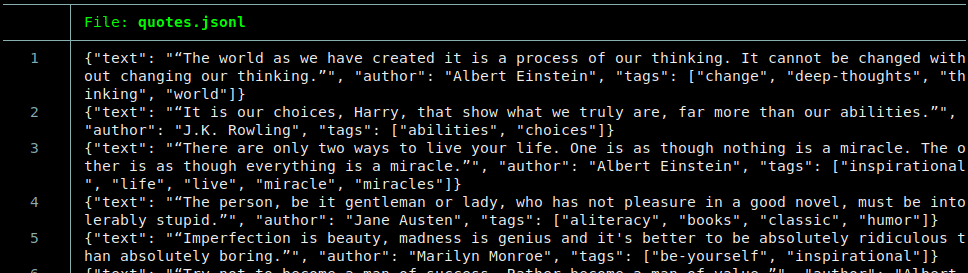
文件尾:
利用 response.follow () 实现分页爬取
将下面的代码替换 tutorial/spiders/quotes.py 文件中的内容:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
"https://quotes.toscrape.com/page/1/",
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("span small::text").get(),
"tags": quote.css("div.tags a.tag::text").getall(),
}
next_page = response.css("li.next a::attr(href)").get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
这里得到与上一个章节同样的结果。
- 与
scrapy.Request()不同,response.follow()方法直接支持相对 URL,不再需要调用 urljoin; -
response.follow()同样返回一个请求实例,用户必须yield这个请求实例; -
可直接传递
href的选择器给response.follow()方法的第一个参数,而非字符串 URL:for href in response.css("ul.pager a::attr(href)"): yield response.follow(href, callback=self.parse) - 可直接用
a元素的选择器:for a in response.css("ul.pager a"): yield response.follow(a, callback=self.parse) - 还可用
response.follow_all()从可迭代对象创建多个请求:anchors = response.css("ul.pager a") yield from response.follow_all(anchors, callback=self.parse) - 最短代码做同样的事:
yield from response.follow_all(css="ul.pager a", callback=self.parse)
章节总结
本章节主要介绍了如何利用 Scrapy 的蜘蛛自动地爬取下一页并提取每一页上面的信息,并且还介绍了用不同的方式实现如何去发出跟踪每一页的请求的代码。
跟踪链接自动翻页实战
本章节要创建一个稍为复杂的新爬虫,用于爬取所有名言作者的详情页面,同时提取需要的数据,以 JSON Lines 的格式输出到文件。并且验证上文到的 Scrapy 链接跟踪和自动翻页技术。
创建蜘蛛
scrapy genspider author "https://quotes.toscrape.com/"
覆盖新创建的代码
关于新蜘蛛的代码,教程已经写好了,可直接复制粘贴到文件(tutorial/spiders/author.py)中:
import scrapy
class AuthorSpider(scrapy.Spider):
name = "author"
start_urls = ["https://quotes.toscrape.com/"]
def parse(self, response):
author_page_links = response.css(".author + a")
yield from response.follow_all(author_page_links, self.parse_author)
pagination_links = response.css("li.next a")
yield from response.follow_all(pagination_links, self.parse)
def parse_author(self, response):
def extract_with_css(query):
return response.css(query).get(default="").strip()
yield {
"name": extract_with_css("h3.author-title::text"),
"birthdate": extract_with_css(".author-born-date::text"),
"bio": extract_with_css(".author-description::text"),
}
上面的代码中:
- 从主页开始,它会跟踪所有指向作者详情页面的锚链接并为每个页面调用
parse_author()回调方法; - 在
parse()方法中对页面的请求回调parse_author()方法,然后在该方法中提取数据,这些数据可以由管道(pipeline)交给 Items 处理;
关于“管道”和“Items” 请参阅文档获取更多的信息: - 用
yield来持续地为每次响应返回该返回的字典数据。 - 该方法中还有个辅助函数,该函数中的
.get()方法添加了一个默认值,当 CSS 查询匹配不到规则时,’response.css()’ 方法就返回此默认值,而不是None。
文档教程中还指出:用户不用担心会有重复的页面被请求,因为在同一次爬取中, Scrapy 会自动过滤掉重复的内容,以及不会再次访问已经访问过的 URL。
开始爬取
scrapy crawl author -O authors.jsonl
这次用上 -O 选项,为的是再次爬取时覆盖原输出文件。
当你阅读到这里时,很大程度上你已经了解和使用 Scrapy 如何跟踪链接和回调的机制。
你也可以了解一下另外一种跟踪链接机制—— CrawlSpider 。
将附加数据传递给回调函数: https://docs.scrapy.org/en/latest/topics/request-response.html#topics-request-response-ref-request-callback-arguments 。
利用蜘蛛参数指定爬取的条件
这是文档教程中的最后一个示例,通过在蜘蛛代码中设定属性,然后在爬取命令中使用 -a 参数指定键值对。
设置好这些,蜘蛛将按 -a 参数指定的属性键值对来过滤爬取的访问,只会访问符合该属性键与值标记的 URL。
爬取命令的选项的阅读,请在终端执行:scrapy crawl --help。
修改代码文件 tutorial/spiders/quotes.py,然后用文档中的代码覆盖:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
url = "https://quotes.toscrape.com/"
tag = getattr(self, "tag", None)
if tag is not None:
url = url + "tag/" + tag
yield scrapy.Request(url, self.parse)
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
}
next_page = response.css("li.next a::attr(href)").get()
if next_page is not None:
yield response.follow(next_page, self.parse)
运行:
scrapy crawl quotes -O quotes.jsonl -a tag=humor
在以上运行的命令中:
-O选项指定从网页提取出来的信息的输出文件,这里选用JSON Lines格式,如果文件扩展名为.json,则使用 JSON 格式,这由 Scrapy 自动判断。-
-a选项指定要过滤的条件,在蜘蛛代码中指定了该属性(用 getattr() 函数,该函数的第二个参数便是),然后用赋值的方式指定tag属性的值。代码中,
tag = getattr(self, "tag", None)表示:获取命令行中由-a选项指定的tag属性的值,然后赋这个值给变量tag。如果
-a选项设为-a tag=humor,则表示仅访问tag值为humor的 URL。此选项要结合实际情况来使用。
全文总结
本文把 Scrapy 的官方文档中的入门教程以容易理解同时使用更多注解的方式编写出来,篇章比较长,但是贵在实用。
这是个优秀的爬虫框架,使用它来爬取网站或者 API 的内容,可以省下许多不必要的代码,从而做到 Python 哲学中的“Write less code, do more”信条。
本文所接触的仅是该爬虫框架能做的其中一点点,要想学习更多,还须继续耕耘和努力。
关于所有的一切都在官方文档中,要是你想更好地使用 Scrapy,写最少的代码,做最多的事,那么有空就多看看文档,边用边学更好。
作者也是个小白,数年前接触过,并且做过一些爬虫项目,但是都没有用到这个框架真正方便的功能,因为不了解,写代码时走了不少的弯路。
最后,非常感谢你看到文章最后作者的啰嗦,祝用好!

鉴于本人的相关知识储备以及能力有限,本博客的观点和描述如有错漏或是有考虑不周到的地方还请多多包涵,欢迎互相探讨,一起学习,共同进步。
本文章可以转载,但是需要说明来源出处!
本文使用的部分图片来源于网上,若是侵权,请与本文作者联系删除: admin@icxzl.com