当在 Linux 下遇到需要分割的大文件时,使用 split 命令进行分割,将它们分割成若干个小文件,到使用时再合并起来,合并后的文件与分割前的文件内容是一模一样的。
本文详解如何使用 split 命令在 Linux 下分割文件,并且使用 cat 命令合并文件。
分割和合并文件的典型举例
先看个例子,当前目录下有个大小为 2GB 的大文件,命名为 testfile.bin。
现有需求把该文件分割为若干个较小的文件,每个小文件大小不大于300MB。
- 这是要分割的大文件:
ls -a -l -h执行结果:

-
以 300MB 为最大单位分割文件,并且最终文件以
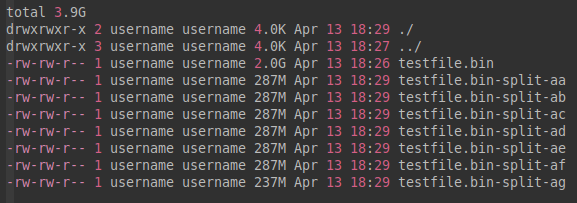
testfile.bin-split-为前缀:split -b 300MB testfile.bin testfile.bin-split- - 上面的命令分割出若干个文件:
再看该目录及文件的大小:
ls -a -l -h执行结果:
-
合并文件:
cat testfile.bin-split-* > testfile.bin-result - 用 MD5 校验原文件与合并后的文件:
username@15:33:13:~$ md5sum testfile.bin-result testfile.bin 71d6441a37e7bbd0799ca2c14ae5761c testfile.bin-result 71d6441a37e7bbd0799ca2c14ae5761c testfile.bin经过 MD5 的校验,以上的两个文件内容一致。

通过上述举例,是不是觉得 split 这个命令很易于使用?然而 split 命令远不止像上面看起来那么简单,它有很多参数,按照参数的设定,提供丰富的分割条件,从而得到不同形式的输出文件。
常用参数
总结一下 split 命令的选项:
-a N或--suffix-length=N:生成后缀的长度;--additional-suffix=SUFFIX:追加额外的后缀;-b SIZE或者--bytes=SIZE:指定每个输出文件的最大大小;-C SIZE或者--line-bytes=SIZE:每行一次切割的字节上限;-d:使用 0 开始的数字作为后缀;--numeric-suffixes:指定文件名后缀的开始数字;-x:使用十六进制数字为文件名后缀;--hex-suffixes:指定十六进制数字为后缀时的开始数字,此时仍然输入的是10进制的数字;-n 或 --number=CHUNKS:将原文件分割成 CHUNKS 个小文件;-e或者--elide-empty-files:不输出空文件,通常与-n一起使用;--filter=COMMAND:对分割生成的文件进行处理,比如压缩生成的文件;-l NUMBER或者--lines=NUMBER:一次分割的行数;-t SEP或--separator=SEP:定义列分割符(代替换行符);-u或者--unbuffered:立即输出到文件;--verbose:打印诊断信息。
基本用法
split 命令的基本格式:split [参数] 文件名 输出文件的前缀/后缀。
上文经典举例中的文件分割命令 split -b 300MB testfile.bin testfile.bin-split-:
-b表示分割后的文件每个的最大大小,格式为“数字单位”,比如“2GB”、“50MB”、“100KB”等等。-
testfile.bin表示分割源文件。按照上面的命令,要将此文件分割为若干个最大为 2GB 的文件。 -
testfile.bin-split-表示分割后各个文件的文件名前缀。依上例来说,生成的分割文件名以“split-”为前缀,后缀计数从字母
a开始,第一个文件以“-aa”为结尾命名,第二个文件以“-ab”命名,依此类推。
若是分割后的文件数目过大,甚至可以得到按类似于-split-cab这样的命名方式命名的目标文件。若是不指定前缀,就以“x”为前缀。
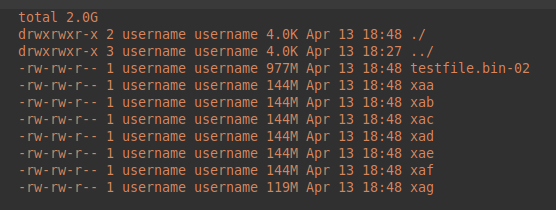
像这样:
username@14:04:41:split-test$ ls -a -l -husername@13:56:26:split-test$ split -b 150MB testfile.bin-02 username@13:57:32:split-test$ ls -a -l -h

参数选项
以下详细解析 split 命令的使用方法。
1. 默认的前缀与分割后文件的大小
- 输出的文件块以“前缀aa”、“前缀ab”…“前缀ax”、“前缀ay”、“前缀az”、“前缀ba”等等方式命名。
-
默认的文件块大小为 1000 行,以及默认的前缀为“x”(英文字母小写“x”)。
-
若是不指定文件,或文件为“-”(减号),那么就读取标准输入。
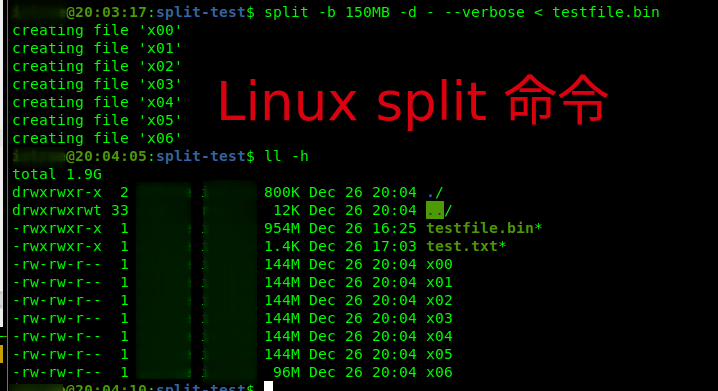
username@14:40:44:split-test$ split -b 2GB - < testfile.bin username@14:42:04:split-test$ ll -h# 上面的分割命令等同于 username@14:40:44:split-test$ split -b 2GB testfile.bin - 长选项的值与短选项的值是一样的,只是使用方式不同。
比如:长选项
--suffix-length=N与短选项-a N的效果是一样的。
2. 设置生成后缀的的长度 -a
设置生成后缀的的长度,默认为“2”。
用法: -a N 或者 --suffix-length=N,“N” 表示后缀的长度,默认为“2”。
举例:
username@14:56:22:split-test$ split -b 200MB -a 3 testfile.bin
username@14:56:34:split-test$ ll -h

举例2:
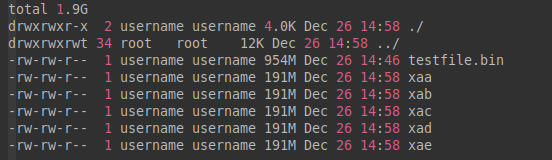
username@14:58:15:split-test$ split -b 200MB -a 2 testfile.bin
username@14:58:21:split-test$ ll -h
举例3:
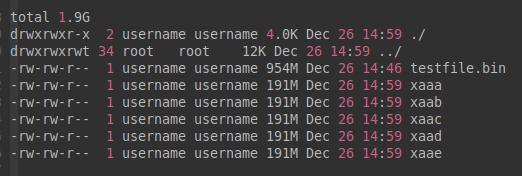
username@14:59:43:split-test$ split -b 200MB --suffix-length=3 testfile.bin
username@14:59:49:split-test$ ll -h
以上皆以默认的“x”为前缀,紧跟着两到三个字母为后缀。
3. 追加额外的后缀到文件名 –additional-suffix
用法: --additional-suffix=SUFFIX。
举例:
username@15:04:42:split-test$ split -b 100MB -a 2 --additional-suffix=SS testfile.bin
username@15:05:18:split-test$ ll -h
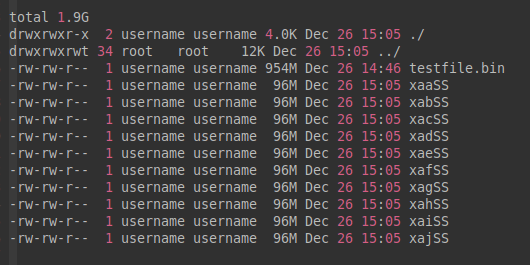
以上举例向后缀的末尾追加了两字母“SS”。
3. 向每个输出的文件放置指定字节的数据 -b
用法:-b SIZE 或者 --bytes=SIZE,“SIZE”指定有单位或者无单位的字节数。
实际用法在本文的《split 命令的基本用法》中已经演示,这里就不再赘述。
4. 每行一次最多切割 SIZE 字节 -C
原文件每行最多切割 SIZE 字节到每个切割生成的文件中,原文件每行剩下的字节输出到下一个输出文件中,下一行将打开新的文件输出。
用法: -C SIZE 或者 --line-bytes=SIZE。
用例:
cat > test.txt <<EOF
Sit itaque eum tenetur neque aliquid, harum Voluptates aspernatur voluptatibus exercitationem illum recusandae voluptas eaque! Vel enim earum rerum quasi sequi. Et porro nulla consectetur quisquam aut Harum ipsum ipsam.
Sit corporis fugit laudantium totam a! Voluptatibus voluptatem distinctio iure eius rem. Nesciunt mollitia saepe iusto dolor id. Eum nisi quos tempora iste laborum Cumque veniam voluptas recusandae ab facilis
Consectetur delectus quaerat dolor maiores impedit harum non. Repudiandae odio tempora tempore voluptate ducimus? Saepe sit doloremque natus cumque nisi Commodi vero et architecto amet quaerat Eius quod dignissimos a!
Amet animi dolore quos cumque animi. Incidunt dolores quis ad
Sit fuga tempore temporibus ipsa
Ipsum veniam aliquid saepe omnis minima quos Ducimus nobis dolore quo esse tempore aperiam Eum iusto fuga minima adipisci temporibus temporibus? Ipsam voluptates itaque possimus natus quidem Optio beatae hic.
Lorem totam beatae debitis iusto suscipit animi, sint
Lorem mollitia modi cum delectus dicta Perspiciatis fuga?
Amet consequatur aspernatur nemo hic ipsam? Ex veniam vero
Amet a quidem voluptatum ea numquam Laudantium in tempore deleniti praesentium at in molestias? Voluptatum sint autem dolores accusamus quas. Quod libero optio rerum quod labore! Dignissimos at odio ullam voluptates nulla? Necessitatibus quod architecto nisi sunt dolore Qui in
EOF
举例:
username@15:57:43:split-test$ split -C 100 < test.txt
username@15:57:45:split-test$ ll -h
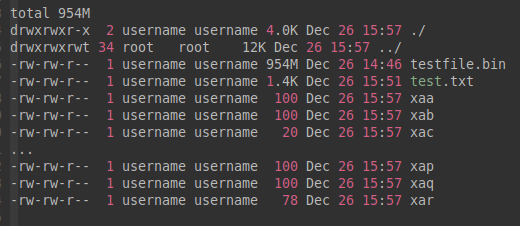
split --line-bytes=100 < test.txt 也有同样的效果。
5. 使用数字为后缀,而非字母 -d
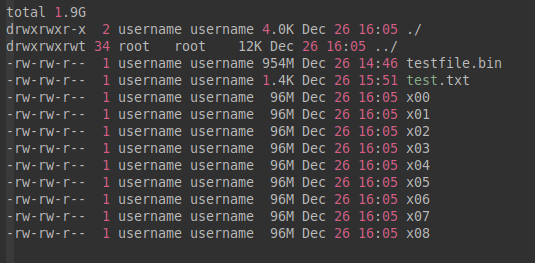
用法:-d。
举例:
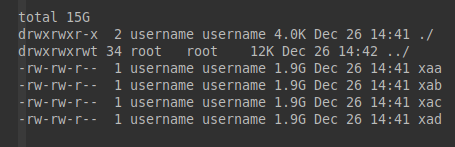
username@16:05:10:split-test$ split -b 100MB -d < testfile.bin
username@16:05:32:split-test$ ll -h
6. 指定以数字为后缀的开始数字 –numeric-suffixes
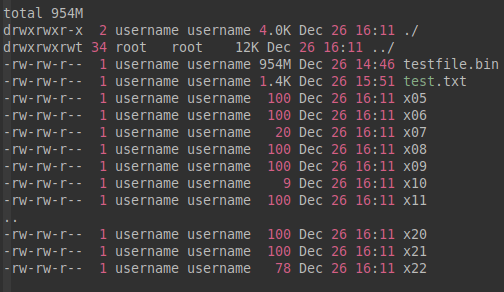
用法: --numeric-suffixes[=FROM],其中的“FROM”指定开始数字,若是不指定“FROM”,那么就与本文上面的 -d 意义一样。
举例:
username@16:11:32:split-test$ split -C 100 --numeric-suffixes=5 < test.txt
username@16:11:34:split-test$ ll -h
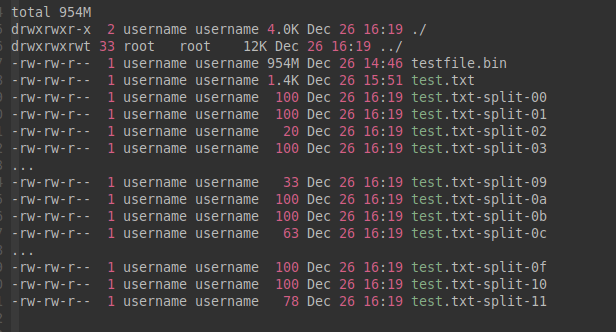
7. 以一个十六进制数值为后缀 -x
用法: -x。
举例:
username@16:19:26:split-test$ split -C 100 -x test.txt test.txt-split-
username@16:19:54:split-test$ ll -h
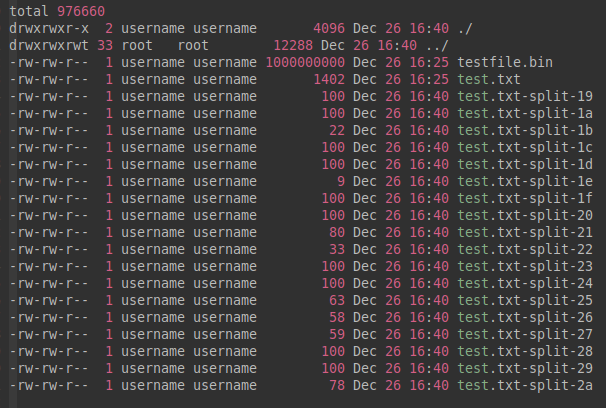
8. 指定开始数字为后缀 –hex-suffixes
指定开始数字仍然以十六进制的方式命名后缀。
用法: --hex-suffixes[=FROM],其中“FROM”可以指定数字,这里实际应用中也是输入的是十进制数字,不过在生成输出文件时会智能地转换为十六进制。
举例:
username@16:40:15:split-test$ split -C 100 --hex-suffixes=19 test.txt test.txt-split-
username@16:40:22:split-test$ ll
9. 一次分割的行数 -l
每次从原文件分割 NUMBER 行输出到输出文件中,每个输出文件中的行数不超过 NUMBER。
也可与 -t(--separator) 选项一起用,此时 -l 表示列数,举例请移步关于 -t 选项的解释。
用法: -l NUMBER 或者 --lines=NUMBER。
不能与 -C 和 -b 等选项混用。
举例:
username@17:03:49:split-test$ split -l 3 < test.txt
username@17:03:53:split-test$ ll -h
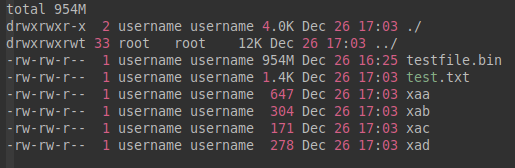
username@17:03:49:split-test$ split --lines=3 < test.txt 也有同样效果。
10. 定义列分割符 -t
使用自定义列分割符分割原文件的行输出到每个输出文件中。
用法: -t SEP 或 --separator=SEP。
要与 --lines 或 -l 一起用。
举例:
username@17:20:29:split-test$ split -t " " --lines=5 < test.txt
username@17:20:30:split-test$ ll -h
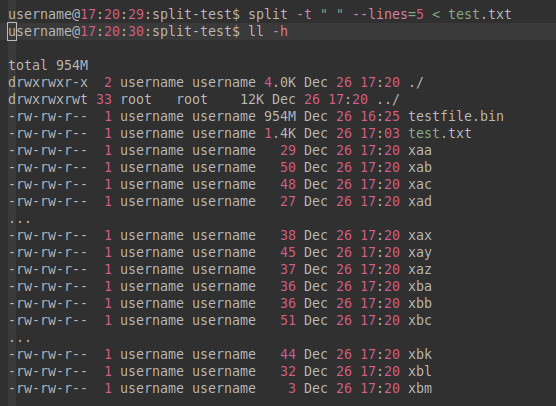
验证“以空格为分割符将每五个独立的部分组成一个文件的一行,且如果当前行到了行尾组不全五个部分,可到下一行提取以组成完整的五个部分”:
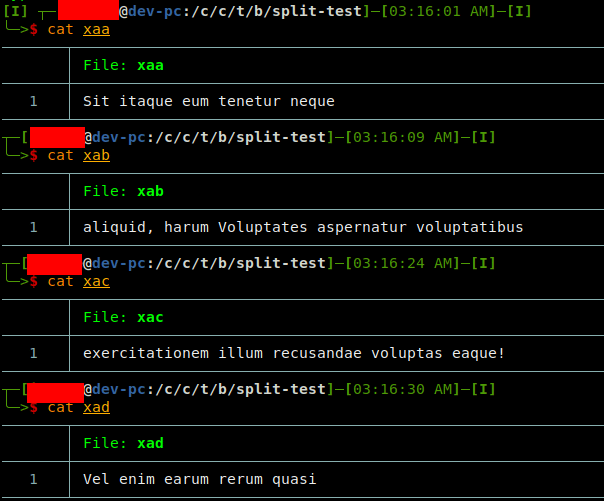
上例中,定义了列分割符 -t " " 为一个空格,然后 --lines=5 指定每次将五个单词放进到分割文件中。其中换行符及下一段落的第一个单词也会计入到上一段最后一个单词中。
11. 立即从输入复制到输出 -u
用法: -u 或者 --unbuffered。
该选项指定立即将分割出来的块输出到文件中,此举会使操作变得缓慢。
12. 打印诊断信息 –verbose
在打开每个输出文件之前输出诊断信息。
用法: --verbose。
举例:
username@17:47:03:split-test$ split -C 100 -d --verbose < test.txt
creating file 'x00'
creating file 'x01'
creating file 'x02'
creating file 'x03'
...
13. 将大文件分割成指定数目的小文件 -n 或–number=CHUNKS
若设定,参数 -n CHUNKS 或 --number=CHUNKS 将根据输入文件的大小分割成其所指定的文件个数。
CHUNKS 的可能值如下:
N:一个数字,split 将把文件分割成 N 个小文件;split -n 30 -e test.txtK/N:在标准输出中输出 N 中第 K 个分割块的内容(这里并不生成分割后的文件,仅输出内容);split -n 10/30 -e test.txtl/N:按行分割成 N 个文件,但在生成的文件中保留原文件中对应的整行,不折断原文件的行。(在 N
>原文件的总行数,或者有足够多的空行时,会生成空(<EMPTY>) 文件,此时要用上 -e 参数保证不生成空文件)split -n l/30 -e test.txtl/K/N:与l/N的基本特征类似,不同的是仅输出第 K 块内容到终端,在这里,-e或许是无效的。split -n l/10/30 -e test.txtr/N:类似于l/N,有些少不同的地方。r/K/N:与l/K/N类似。
使用 Shell 命令处理生成的文件 –filter
在生成小文件后,可能有对这些文件进行压缩、重命名,或者移动到其他目录的需求,这时可以传入 --filter=COMMAND 参数,其中,COMMAND 中一系列的 Shell 命令,比如:
split -n 10 -e --filter='gzip > $FILE.gz' test.txt
# 或者
split -n 10 -e --filter='
# 这里可以有多条命令
gzip > $FILE.gz
echo $FILE
' test.txt
# 解压 gzip -d filename
总结
本文详细介绍了 Linux 下 split 命令的使用方法,涵盖文件分割与合并的全流程。通过典型示例展示如何按大小(如 300MB)分割大文件,并验证分割后文件的完整性(MD5 校验)。文章系统解析了 split 的常用参数,包括设置后缀长度、行数/字节限制、数字或十六进制后缀、列分割符等功能,并演示了如何通过 cat 合并文件。内容适用于需要高效管理大文件的场景,如日志拆分、数据备份等。
另:倘若
split退出状态为零表示成功,非零值表示失败。

鉴于本人的相关知识储备以及能力有限,本博客的观点和描述如有错漏或是有考虑不周到的地方还请多多包涵,欢迎互相探讨,一起学习,共同进步。
本文章可以转载,但是需要说明来源出处!
本文使用的部分图片来源于网上,若是侵权,请与本文作者联系删除: admin@icxzl.com